Blog move
This blog has been moved to join our website at http://www.alanpaull.co.uk.
To continue receiving updates please subscribe to the blog at it’s new location.
Privacy vs Data
I recently read OUseful’s post “Participatory Surveillance: Who’s been tracking you today?” (really want a Trackr or five now…) and then happened to read Tribal’s post “Without data student information is nothing” and the juxtaposition of the two really got to me.
There’s a lot these days (I hate that phrase…) about how we’re losing privacy left, right and centre and how we must protect it at all costs or be outraged that companies like Google and Facebook don’t have the right privacy policies that work for absolutely everyone. Don’t get me wrong: privacy is important for a great many things (banking is the one that really comes to mind), but the perfect privacy ship sailed a long long time ago. Any notion that we can somehow go back to a point where all and sundry don’t know at least our shopping habits is ridiculous and not actually necessarily desirable.
Because then we have the flip side of the coin: data. Wonderful, glorious data! Data that we could never have conceived of having let alone thought up the uses for even 5 years ago. On just our phones most of us now have health data, shopping data, banking data, location data, contacts, browser history, game data…the list goes on and on. And when we start mixing some of those datasets together (either with more of your own data or other people’s data) magic can happen.
Take the Tribal article linked to above. It has this picture of some of the data University’s probably already have about their students.

Picture from TribalGroup
And this is by no means exhaustive. Imagine the support that could be provided for students with the right ways of analysing this data. Provide the right summaries to student tutors and you could have a truly individually tailored learning experience, where your tutor understands that you prefer to work off campus and can’t always attend all your lectures, but have every book on the subject out from the library and spent crazy amounts of time on the VLE catching up on notes and being an active member of discussions there. Or that you come to every lecture, but mostly to sleep and have never cracked a book or been on the VLE except at induction, and judging from your previous academic history barely even scraped a place. Or even that you’ve really intended to join in the discussions on the VLE, but you have 5 calls in to support right now and maybe you need a bit of help chasing those up. The possibilities are mind-boggling.
But this would mean that someone is (gasp!) tracking your data. Logging it even. Maybe even storing it so that it can follow you throughout your academic career from the very start. The question is whether we are prepared to give up our privacy for the benefits.
I, for one, welcome our new data overlords. So much is done with our data already from commercial reasons, I say let’s at least exploit it as much as we can for useful reasons as well.
What do you think? Where would you draw the line between privacy and data?
UCAS Postgraduate Launch
The new UCAS Postgraduate system is up and running, replacing the old Data Collection system (at least for PG).
We’ve been looking forward to having a look at this new system for a number of reasons, not least of which is that UCAS has put some substantial effort into keeping institutions apprised of progress as it was being developed with regular webinars. Even more: they seem to have taken on board a lot of what people have been asking for, so, in theory, this should be a more straightforward system to use. I’ve already spotted (and used) the feedback button on the course editing side – we can only hope that people will give feedback and it will be taken into account. If so, this system could end up being one of the better ones to use.
What’s really got us excited though is that UCAS confirmed all the way through the process that this system will be taking XCRI-CAP feeds! Anyone who’s worked with us will know that we’ve been working with XCRI-CAP right from helping to write it all the way through so many projects, the Course Data Programme and now we’re working with Prospects to get it rolled out for PG courses. It’s fantastic to have another aggregator on board. As the British Standard for communicating course marketing information it is just what is needed to get consistency and accuracy across all aggregators.
We were warned that XCRI-CAP functionality would not be up and running straight away, but we have hopes that in the next couple of months there will be an update to include it. Looking at the course editing area it certainly looks well structured for XCRI-CAP and I can’t wait to try setting up a feed. As course marketing distributors for Birkbeck, University of London and The OU this will save us, and them, a lot of time once it’s ready as no keying will be needed for Prospects or UCAS PG.
To find out more about XCRI-CAP take a look at the XCRI website. For free support creating your own XCRI-CAP feed contact me at jennifer@alanpaull.co.uk.
Happy International Service Design Day! Service Design in Higher Education Enrolment
That’s a heading I never thought I’d write – but why not? Service Design methods make services that work for everybody, and in an increasingly service oriented culture it’s something we desperately need more of.
A couple of years ago we were fortunate enough to have the opportunity to do some Service Design work with a University in the North around student enrolment. The standard enrolment period in September/October is a busy time for students, many of whom are leaving home and working out life stuff for themselves for the first time. This University was finding low student satisfaction with the enrolment process, and we were brought in to look at it from the students’ points of view specifically to see what changes could be made.
Here is some of the advice we were able to give on enrolment:
Make it a celebration!
Yay! You made it! Welcome to University! Here are all the wonderful things you’re going to be able to see and do and learn now that you have your student card!
So often Universities see enrolment as a series of necessary admin tasks to drag these poor students through and get over and done with. Students are often left worn out, confused, saddened and a little lost in all the drudgery. The key point we wanted to make was that this may be a peak of annoying work for staff, but for each individual student this is a huge event, which colours their entire view of the University, and the choices they’ve made to get there. At every stage it should be treated as a celebration – they’ve done well, they’ve arrived at something they’ve been striving for, and, yes, the next couple of months are going to be tricky while they find their feet, but the message at every turn needs to be that this tricky spot is going to be worth it, and they are going to be supported.
Welcome to the 21st Century
Many Universities are notorious for an unwillingness to let go of paper processes. While some have embraced the online revolution, I think it’s safe to say that most are a bit behind the curve. For every bit of paper a new student has to remember to bring to the right place at the right time, there is a chance for the system to break down. So let go of paper – wherever possible, let students provide information electronically. Preferably get them to do it in advance, so that you can let them know exactly what’s outstanding, before they make a potentially very long journey to get to you. Some things will still need to be done in person and will need to involve paper, but the less paper you require, the better it will be for everyone.
The Space-Time Continuum
A timetable that requires a student to be in two places at once is about as helpful as one that requires them to travel to campus from their job/childcare arrangements/home two buses away for 5 mins before leaving again.
The enrolment timetable may be the trickiest part of the whole enrolment experience, but arguably the one that will make it go smoothest. No one wins when students are pulled in every direction at once. Universities have mastered this (to an extent) when it comes to timetabling teaching time, but enrolment activities tend to be organised in a separate process that can leave students with decisions about whether to go to their very first lectures or induction events or get their finances sorted. But the geography of these things also needs to be considered: making students run half a mile across an unfamiliar campus because of appointments that almost, but don’t quite, overlap, is stressful and isn’t likely to result in the enrolment processes running on time either.
Although staffing large chunks of time is obviously a problem, any flexibility that can be given to students will ease their constraints and make them more likely to be physically capable of making it to their appointments…whether they actually turn up of course depends on the student.
It’s the little things
As anyone familiar with Service Design will probably be aware, most people actually don’t mind queuing (and we’re not just talking about the British). Give them some space, a nice environment, some idea of how long it’s likely to be and a chance to sit down, and people aren’t generally too fussed. It’s a bonus if you can provide some form of entertainment, even if that’s just information about the next stages of enrolment, or doctor’s surgery magazines. This should not need to be said but: kettling is never pleasant.
Signage was the other big problem we found at this particular University: having a sign on a door that they need to go into say “Authorised personnel only” because that’s true for the rest of the year, isn’t terribly helpful. Walk through the spaces you want your students to walk through – it’s the biggest boost you can give to your process.
On doing a bit extra for your students: this is a stressful time for most of them, and there will be those who have extra needs in order to manage this. If you can provide a well signposted quiet space for students to take a breather before diving back into the melee, it can make their lives a little easier. And this doesn’t just have to be for students who have medically diagnosed needs: plenty of other students value a chance to have somewhere to collect themselves.
These are just some of our headline points on Service Design in enrolment, and we’d love to hear about your experiences – leave us a comment if you’ve been through this process in your University.
If you would like more information about our findings on enrolment processes, or help with Service Design in your University, please get in touch at jennifer@alanpaull.co.uk.
Collectible Course Information: A Quick Look at UCAS’ Course Collect
We’ve been working recently with a couple of our university clients on the brand spanking new UCAS Course Collect system. This is a data entry service, or if you prefer, a part of the UCAS website where you can key in courses information. It captures information for course marketing purposes and relevant stuff for the UCAS admissions system. It replaces the old netupdate / web-link for courses.

Course Collect Screen Shot
Like all new systems, Course Collect has had a few teething troubles from a university or college perspective. Getting used to a new system for keying is always a bit of a trial, and Course Collect gathers more data within a more structured information model, so it’s almost bound to be complex. We now have Programme > Subject Option >Course > Stage as the structure instead of the very flat one in netupdate. So there’s more flexibility in how the data is represented, but a greater demand for data on universities and colleges.
Data was migrated in May from the old netupdate service, so our early summer has been taken up with checking the data, amending errors on migration, and adding in new courses to be ready for Clearing and then the new season. And of course, we’re managing both 2013 and 2014 entry data.
Particular problematic areas were:
- Some slight glitches in approving migrated data, especially where the migrated data was too large for the new field size. This took a few weeks to resolve.
- Paging of lists limited to 15
- Establishing how to get entry requirements information to appear in the right place in the new course finder tool on the UCAS website, which uses Course Collect data.
- Complications around showing admissions tests and esoteric prerequisites
- An annoying lack of Help in the Help system
- A rather messy mess in the Entry Profiles area, which won’t be settled until early September
- And at the moment it doesn’t want to work on my Chrome setup.
As we’re really XCRI-CAP people at heart, we continue to encourage UCAS to dispense with this old-fashioned ‘key everything in’ method of data collection and to adopt the XCRI-CAP information standard for bulk updating. To that end I’ve [ed: Alan that is] been doing some mapping of XCRI-CAP to UCAS Course Collect, and also having some thoughts about how a process of getting XCRI-CAP data into the UCAS system might be made to work.

Draft Course Collect Bulk Update Process
Our conclusion on Course Collect is ‘the jury’s still out’. Now that we’re down to maintaining the data and only adding in new courses occasionally, it might represent an improvement on the old services. However, my personal view is that we need some good quality management and reporting facilities, and a better workflow sub-system to bring this service up to ‘good’.
More Salami please!
We’ve made some small changes to our Salami demonstrator. Jen has pulled in some useful data from the LMI for All API – details of the latter are on the UKCES LMI for All web page. The new version of the Salami HTML Demo is here: http://81.187.183.45/Salami_1/salami_1.
LMI for All has a range of information, including estimated hours and estimated salaries for particular ranges of jobs. These are determined by SOC Code, as shown in the example here for structural engineer (SOC Code 2121, which covers a range of engineering jobs):

New Salami Lmi Screen Shot
You can also pull in information about actual job vacancies from the LMI for All API; it uses the Department for Works and Pensions Universal Jobmatch database as source data. We’re not yet pulling these in, because currently there’s no suitable coding on the Universal Jobmatch data to link it in. However, it’s a ‘watch this space’ situation.
Today is our day for the dissemination of our MUSAPI project outputs, which Kirstie and I (amongst others) are presenting via a webinar on Blackboard Collaborate. This will briefly feature our Salami Course>Job Profile button, as well as the MUSAPI demonstrator, of which more later. Before you dash away to use the demo, just a quick note that we’re still working on it, so use with caution!
A slice of Salami: integrating course and job profile searching
The Salami Layer
We’ve been developing a prototype of the ‘Salami Layer’ idea first mooted a while back as a result of the University of Nottingham’s Salami project. This is all about linking data together to make useful services for people, and to provide more nodes in a growing network of interoperable data.
Salami focused on labour market information. We’ve been taking it forward in the MUSAPI (MUSKET-SALAMI Pilots) project with a view to producing a hybrid service (or services) that use both the MUSKET text description comparison technology and the SALAMI layer material to link together courses and job profiles.
Salami HTML Demo
Thanks to the skill of our newest member of staff at APS (Jennifer Denton), we now have a demonstrator here: http://81.187.183.45/Salami/salami. It uses recently published XCRI-CAP feeds from The Open University, Courtauld Institute and the University of Leicester as the source of its courses information (noting that these are not necessarily comprehensive feeds). Job Profile information has come from Graduate Prospects, from the National Careers Service and Target Jobs.
The purpose of the demonstrator is to show how we can link together subject concepts that are used to find courses with occupation concepts used to find job profiles. It relies on classifying courses with appropriate terms, in this case JACS3, for the discovery of relevant courses, mapping subject concepts to occupation concepts and then linking in the job profiles. This last task was done by attaching them to the occupation terms (in this case CRCI – Connexions Resource Centre Index – terms), rather than by searching – that will come later. All of these bits were wrapped up in a thesaurus. We then made it all go via a MySQL database, some Java code and a web page. There are some sharp edges still as we haven’t finished cleaning up the thesaurus, but I think it shows the principles.
We haven’t used random keywords, but well known classification systems instead, so that we can develop a discovery service that produces relevant and ranked results (eventually), not just a Go0gle-style million hits listing.
The way the demonstrator works is as follows:
- Select a term from the drop-down list at the top. This list consists of our thesaurus terms of a mixture of academic subjects for searching for courses and occupation terms for searching job profiles. You can start typing, and it will go to that place on the list. For example try “History of Art”.
- Then click Select. This will bring up a list of Related Terms (broader, narrower and related terms with respect to your selection), Subject/Occupation Terms (if you’ve picked a subject, it will show related Occupation Terms; if you picked an occupation, it will show related Subject Terms); and Links to Further Information.
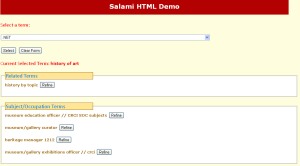
- Salami Demo 1

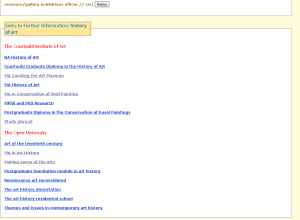
- Salami Demo 2

- You can navigate around the search terms we use by clicking on the Refine button next to the entries in the Related Terms and Subject/Occupation Terms lists. For example, if you click on Refine ‘history by topic’, this changes your focus to the ‘history by topic’ subject, and you can then navigate the subject hierarchy from there. If you click on Refine ‘heritage manager’, this changes your focus to that occupation and you can further navigate around jobs about information services or various subjects.
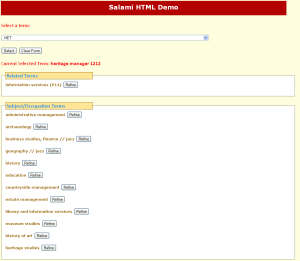
- Salami Demo 3

- At the bottom of the page we have a list of links to further information. These will be either links to relevant courses or to job profiles. The former are drawn from XCRI-CAP feeds, the latter are currently hard-wired into our thesaurus – we’re currently developing a method of using live searches for both types of link. For example, for “heritage manager” we have links to Graduate Prospects and Target Jobs profiles for Heritage Manager.
The upshot of the demonstrator is that we can show how to integrate the discovery of both courses and job profiles (and later on, job opportunities) using a single search term.
Oh-So Thesaurus
The technological underpinning of this is our thesaurus, which has the following broad components.
- A ‘master’ table of thesaurus terms with attached classifications (in particular JACS3 for subjects and CRCI for job profiles).
- A table of occupation-subject term links (O>S)
- A table of subject-occupation term links (S>O)
- A table of occupation-profile links, currently for implementation of the job profile URLs.
Inclusion of JACS3 codes on the course records and occupation codes on the job profiles is key to the discovery process, so that we can focus on concepts, not string searching. This means, for example, that a search for ‘history of art’ will find courses such as ‘MA in Conservation of Wall Painting’ or ‘MA in Art History’ (Courtauld Institute and Open University respectively), even though neither of the records or web pages for these courses contains the string ‘history of art’.
Perhaps more importantly we can find out that, if we’re interested in the history of art, there are several job areas that might well be relevant, not simply work in museums and galleries, but also heritage manager – and if we browse only one step from there, we can find occupation areas in the whole world of information services, from archaeologist to social researcher, from translator to patent attorney. And all of these possibilities can be discovered without going from this service to any form of separate ‘careers search’ website.
Further extensions
Our Salami demonstrator suggests that this approach could be extensible to other areas. Perhaps we can link in standard information about qualifications, just a short hop from courses. Maybe we can classify competencies or competence frameworks and link these to courses via vocabularies for learning outcomes / competence / curriculum topics.
The other strand in MUSAPI is the textual description comparison work using the MUSKET technology. Even via our Salami demonstrator, your lists are bald undifferentiated lists. If we can capture a range of search concepts from the user – parameters from their current circumstances, past skills, experience, formal and informal education and training, and aspirations – then we could use the MUSKET tools against the Salami results to help to put the results in to some form of rank order. The user would then be able to refine this to produce higher quality results in relation to that individual’s needs, and our slice of salami will have stretched a long way.
Consuming XCRI-CAP III: Skills Development Scotland
Skills Development Scotland has operated a data collection system called PROMT for many years. PROMT is a client application (not browser-based) that sits on your computer and presents you with a series of screens for each course you want to maintain. Each course may have many ‘opportunities’ (these are the same as XCRI-CAP presentations) with different start dates, visibility windows and other characteristics. Many fields in PROMT have specific requirements for content that make the experience of keying not particularly enjoyable (though it has been improved since first launch).
With OU course marketing information consisting of several hundred courses and over 1,000 opportunities, it was with some relief that we at APS (running 3rd party course marketing information dissemination for The OU) turned to the SDS’ Bulk Update facility, using XCRI-CAP 1.1. We had been nervous of using this facility initially, because PROMT data is used not only for the SDS’ course search service, but also has a direct link to a student registration and tracking service for ILAs (Independent Learning Accounts; for non-Scottish readers, ILAs continued in Scotland even though they were discontinued for a while south of the border). Students can get ILA funding only for specific types of course, so each course/opportunity has to be approved by Skills Development Scotland. Changes to the course marketing information can result in ILA approval being automatically rescinded (albeit temporarily), which can mean the provider losing student tracking details, and therefore being at risk of losing the student entirely. So naturally we decided to do some careful testing in conjunction with both SDS and our colleagues at The OU’s Scottish office.
Fortunately we discovered that when we uploaded opportunities the system added them on to existing records, rather than replacing them, so student tracking was unaffected. In addition, individual fields of course records for existing courses was over-written but the records remained active and opportunities were unchanged. These features meant that data integrity was maintained for the opportunity records, and we could always revert to the existing version and delete the new, if necessary.
We were able to load new courses with new opportunities, and also existing courses with new opportunities with no significant problems. The potential ILA difficulty was somewhat reduced, because The OU’s information for an individual opportunity does not need to be updated once it has been approved for ILA; our main reason for updating opportunities themselves was to add in fees information, but cost information has to be present before an opportunity can gain ILA approval, so this type of update would not interrupt ILA approval or student tracking.
Owing to requirements for some proprietary data, for example numerical fees information and separate VAT, not everything could be captured through XCRI-CAP. However, using the PROMT interface for checking the data, adding in very small extras and deleting duplicated opportunities was comparatively light work, as the mass of it was handled by the XCRI-CAP import.
Strikingly good parts of our Bulk Update process (apart from the obvious vast reduction in keying time):
- Use of a vocabulary for qualification type in PROMT. This made it easy to use various rules to map from The OU data to the required qualification grouping. These rules included a close examination of the content of the qualification title in the XCRI-CAP data to make sure we mapped to the correct values.
- For some elements, use of standardised boilerplate text in specific circumstances, again identified by business rules.
- Good reporting back from the SDS Bulk Update system on the status (and errors) from the import. This included an online status report showing how many records of each type had been successfully uploaded, with date and time, after a few minutes from the time of loading.
- The system permits us to download the whole data set (well, technically as much as could be mapped) in XCRI-CAP 1.1 format, so we were able to compare the whole new set of records with what we expected to have.
- The ability to review the new data in the PROMT client interface within minutes of the Bulk Upload. This gives a great reassurance that nothing’s gone wrong, and it permits rapid checking and small tweaks if necessary.
I see this combination of bulk upload with a client or web-based edit and review interface as an excellent solution to course marketing information collection. This push method of data synchronisation has the advantage of maintaining the provider’s control of the supply, and it still permits fine-tuning, checking and manual editing if that is necessary. In contrast a fully automatic ‘pull’ version might leave the provider out of the loop – not knowing either whether the data has been updated, or whether any mistakes have been made. This is particularly important in cases where the collector is unfamiliar with the provider’s data.
XCRI-CAP: turn 12 days of keying into 3 hours of checking.
Consuming XCRI-CAP II: XCRI eXchange Platform (XXP)
XXP experiences
Since I helped to specify the XCRI eXchange Platform, and I’m currently seeking more institutions to use it, I do have an interest. However, I don’t do the very techie, database development or systems development work on it, so I’m more a very experienced user and partially designer.

The purpose of XXP is to provide an XCRI-CAP service platform, so it has facilities for loading XCRI-CAP data, though not yet fully automatic ones. The platform has been designed specifically for XCRI-CAP, so its main functions are to provide input and output services that are likely to be relevant to the community. For example, it has CPD and Part Time course data entry facilities, enabling providers to key and maintain these types of course very easily, with vocabularies optimised for the purpose. There is also a CSV loader for those who can output CSV but not XCRI-CAP – this effectively provides a conversion from CSV to XCRI-CAP 1.2, because like all the XXP services, loading in the data enables creation of output XCRI-CAP feeds (both SOAP and RESTful).
Importantly XXP has a feed register (discovered by our Cottage Labs colleagues for their Course Data Programme demonstrator project), so that you can discover where the feed is, who’s responsible for it, what it covers and so on.
XXP is defined by the input and output requirements that APS and Ingenius Solutions have currently provided in response to their perception of market demand. This necessarily changes as more institutions get their data sorted out. While the focus in XXP is on acting as an agent for a provider (a university or college), XXP is effectively an interface between the provider and other aggregating organisations. It enables the creation of ‘value-added’ feeds enhanced by extra data (such as addition of vocabularies, like those for course type, or subject) and by transformation of data (typically concatenating or splitting text fields, or mapping from one classification system or vocabulary to another).
Getting XCRI-CAP data into XXP is at the moment not completely automatic. The main routines are through a manual load – which is fairly time consuming – or through an automatic CSV load (data2XCRI service), requiring a CSV file. In fact (and somewhat bizarrely) it’s not difficult to produce the CSV file from an existing XCRI-CAP file, then load it in. This is a stopgap measure till XXP has a fully functioning XCRI-CAP loader.
My use of the XXP consumption of XCRI-CAP at the moment has been using a push method – I stay in control of the operation and can make sure it all works as expected. XXP has a straightforward read-only View function so you can see the data in the system when loaded. If changes need to be made, then you make them at source (upstream); if there was an edit function for the XXP-loaded data, you would wipe out changes when you next loaded the data in.
As the data content going into XXP is controlled directly by the provider, XXP imports whole data sets, not updates. This simplifies the process considerably on both sides, which can focus entirely on live complete data sets. Maybe this needs a bit more explanation. I figure that if the provider controls the data, then the current data in XXP won’t have been ‘enhanced’ by manual edits or upgraded data. Therefore, it’s safe to completely overwrite all the data for the provider – that won’t wipe out anything useful that we’re not going to add back in. This is in contrast to ‘delta update’ methods that compare old and new data sets and just pump in the changed material. It’s much simpler, which has some merit.
Some of the difficulties that had to be overcome in the XXP aggregation:
- Use of URLs as internal identifiers (ie inside XXP) for linking courses and presentations – this is overcome either by using a new-minted internal identifier or by re-constructing it (keeping the unique right-hand part).
- On-the-fly refinements using xsi:type – this is a technical problem as many tools don’t like (read: tolerate) xsi:type constructions, or indeed any type of redefinitions, extensions or restrictions. This requires workarounds for or at least careful handling of extended <description> types.
- Non-normalised material in XCRI-CAP structures. For example, <venue> is nested in presentations, therefore repeated. As the XCRI-CAP is parsed, you may find new venues or repeated venues that need to be processed. Ideally all venues should be processed prior to course>presentation structures, so it may be best to pass once through the file to discover all the venues, then a second time to populate the rest.
- Incomplete bits. For example, the venues referred to in the previous bullet may simply have a title and postcode. XXP has a facility for adding missing data to venues, so that the output XCRI-CAP feed can be more complete.
- Matching of vocabularies. Some feeds may use JACS, others may use LDCS, others simply keywords, and yet all the data goes into a subject field – this requires a method to store the name of classification and version number (JACS 1.7, 2 and 3 are substantially different).
A substantial advantage of XXP is that once you’ve put the data in (in whatever format), you can get it out very easily – currently as XCRI-CAP SOAP and RESTful getCourses, but there’s no reason why other APIs couldn’t be added for JSON, HTML, RDF and so on. This effectively means that XXP can have mapping and transformation services into and out of XCRI-CAP, adding value for particular ‘flavours’ or for new versions.
XCRI-CAP: turn 12 days of keying into 3 hours of checking.
Consuming XCRI-CAP I
This post and a few later ones will be some musings on my experiences of how XCRI-CAP is or might be consumed by aggregating organisations and services. I’ll not go into the theoretical models of how it could be done, but I’ll touch on the practicalities from my perspective. Which, I admit, is not as a ‘proper’ technical expert: I don’t write programmes other than the occasional simplistic perl script, neither do I build or manage database systems, other than very simple demonstrators in MS Access, and I dabble in MySQL and SQL Server only through the simplest of front end tools.
My main XCRI-CAP consuming efforts have been with four systems: XXP, Trainagain, Skills Development Scotland’s Bulk Import Facility and K-Int’s Course Data Programme XCRI-CAP Aggregator.
XXP characteristics
- Collaborative working between APS (my company) and Ingenius Solutions in Bristol
- Service platform for multiple extra services, including provider and feed register (for discovery of feeds), AX-S subject search facility, CSV to XCRI converter, web form data capture, getCourses feed outputs (SOAP and RESTful)
- Doesn’t yet have an auto-loader for XCRI-CAP. We can load manually or via our CSV to XCRI facility.
Trainagain characteristics
- Existing system with its own established table structure, its own reference data and own courses data
- SQL Server technology
- I have off-line ‘sandbox’ version for playing around with.
Skills Development Scotland Bulk Import Facility characteristics
- XCRI-CAP 1.1 not 1.2
- Existing live XCRI-CAP aggregation service (push architecture)
- Works in conjunction with the PROMT data entry system
K-Int XCRI-CAP Aggregator characteristics
- Built on existing Open Data Aggregator, a generalised XML consuming service.
- Takes a ‘relaxed’ view to validation – not well-formed data can be imported.
- Outputs JSON, XML and HTML. But not XCRI-CAP.
These are early days for data aggregation using XCRI-CAP. There’s been a chicken-and-egg situation for a while. Aggregating organisations won’t readily invest in facilities to consume XCRI-CAP feeds until a large number of feeds exist, while HEIs don’t see the need for a feed if no-one is ready to consume them. The Course Data Programme takes the second one of these (I guess that’s the egg??) problems – if we have 63 XCRI-CAP feeds, then we should have a critical mass to provoke aggregating organisations to consume them.
Some of the questions around consumption of XCRI-CAP feeds centre on technical architecture issues (Push or Pull?), what type of feed to publish (SOAP, RESTful, just a file?), how often should the feed be updated and / or consumed (real-time updating? weekly?, quarterly? annually? Whenever stuff changes?), how do the feed owners know who’s using it? (open access v improper usage, copyright and licencing). Some of these issues are inter-related, and there are other practical issues around consuming feeds for existing services – ensuring that reference data is taken into account, for example.
I’ll try to tease out my impressions of the practicalities of consuming XCRI-CAP in various ways over the next few blog posts.
XCRI-CAP: turn 12 days of keying into 3 hours of checking.
